A trimodal scope
We isolate work where audio, visual signals, and language participate as inputs, outputs, supervision, prediction targets, or evaluation criteria.
Preprint version · 2020-2025 literature · Figures from the paper
This survey treats audio, vision, and language as a joint modeling problem, rather than three loosely connected modality areas. It organizes recent AVL work for understanding, generation, reasoning, benchmark selection, and future-work citation.
Why this survey?
Audio-visual learning and vision-language modeling have often been studied as separate or bimodal research lines. Recent systems increasingly require sound, visual context, and natural language to interact within the same task, model, supervision signal, or evaluation protocol.
This survey focuses on that trimodal setting. It organizes recent work by modality use, representation learning, alignment and fusion mechanism, task formulation, benchmark, and open challenge.
What this survey gives you
We isolate work where audio, visual signals, and language participate as inputs, outputs, supervision, prediction targets, or evaluation criteria.
We organize AVL methods by how they represent each modality, align signals across modalities, and fuse information for understanding or generation.
We map common AVL tasks, datasets, and metrics, and highlight gaps in temporal alignment, causal correspondence, interpretability, long-context reasoning, and efficient deployment.
Explore the survey
Use the index to locate tasks, mechanisms, benchmark choices, and open problems without reading the full preprint first.
Showing 9 of 9 tasks
Question: How do models use audiovisual and language cues to recognize actions?
Input / Output: video/audio/text cues → action labels
Representative datasets: Kinetics-400, EPIC-KITCHENS
Metrics: Top-1, Top-5, Accuracy, F1
Use this survey when citing: task organization for AVL understanding benchmarks.
Question: How do models infer emotion or sentiment from audiovisual dialogue and text?
Input / Output: dialogue signals → emotion or sentiment
Representative datasets: IEMOCAP, MELD, CMU-MOSEI
Metrics: Accuracy, F1
Use this survey when citing: emotion and sentiment tasks that combine speech, visual behavior, and language.
Question: How do models answer language questions about audiovisual scenes?
Input / Output: audiovisual scene + question → answer
Representative datasets: Music-AVQA, VAQA
Metrics: Answer accuracy
Use this survey when citing: benchmark organization for AVL reasoning tasks.
Question: How do models localize objects or regions using audiovisual and textual queries?
Input / Output: audiovisual-textual query → localized object
Representative datasets: RefCOCO, Flickr-SoundNet
Metrics: Localization accuracy, IoU
Use this survey when citing: grounding and localization formulations in AVL understanding.
Question: How do models identify what event happens and when it occurs?
Input / Output: audiovisual stream → event class and time span
Representative datasets: AVE, LLP
Metrics: Accuracy, F1, localization quality
Use this survey when citing: temporal evaluation in audiovisual-language understanding tasks.
Question: How do models retrieve matching items across audio, video, and language?
Input / Output: query in one modality → ranked items in another
Representative datasets: MSR-VTT, AudioCaps
Metrics: Recall@K, median rank
Use this survey when citing: retrieval-based evaluation for cross-modal AVL alignment.
Question: How do models use visual speech cues and audio to produce transcripts?
Input / Output: speech video + audio → transcript
Representative datasets: LRS2, LRS3
Metrics: WER
Use this survey when citing: generation-oriented AVL tasks and evaluation protocols.
Question: How do models generate language descriptions from audiovisual clips?
Input / Output: audiovisual clip → caption
Representative datasets: MSR-VTT, ActivityNet Captions
Metrics: BLEU, METEOR, CIDEr
Use this survey when citing: captioning tasks that condition language generation on audio and visual evidence.
Question: How do models use text or audio conditions to generate video?
Input / Output: text/audio conditions → video
Representative datasets: AudioSet-Cap, Landscape
Metrics: FVD, CLIP similarity, human preference
Use this survey when citing: generative AVL tasks and evaluation gaps beyond text-only generation.
No tasks match the selected filters.
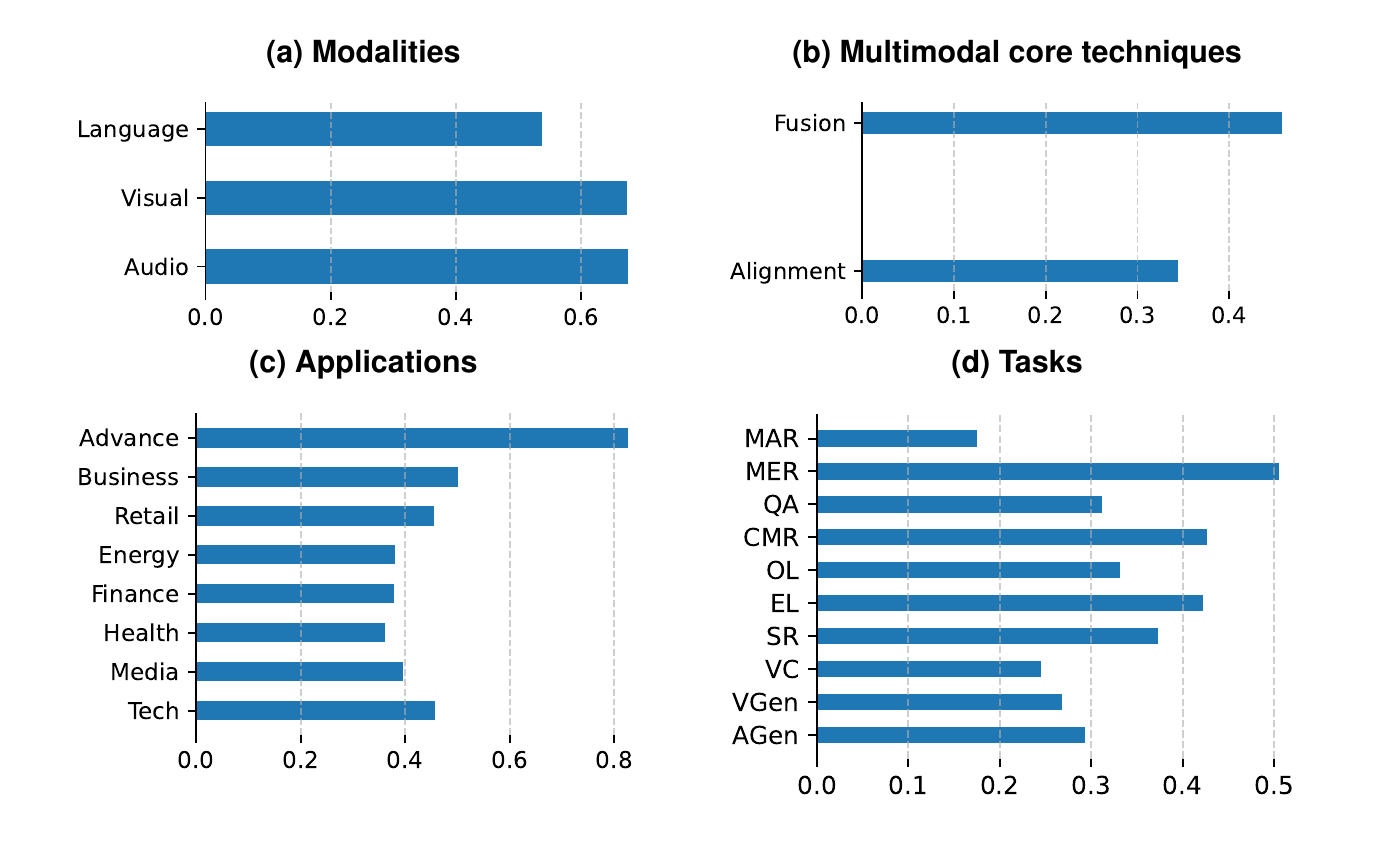
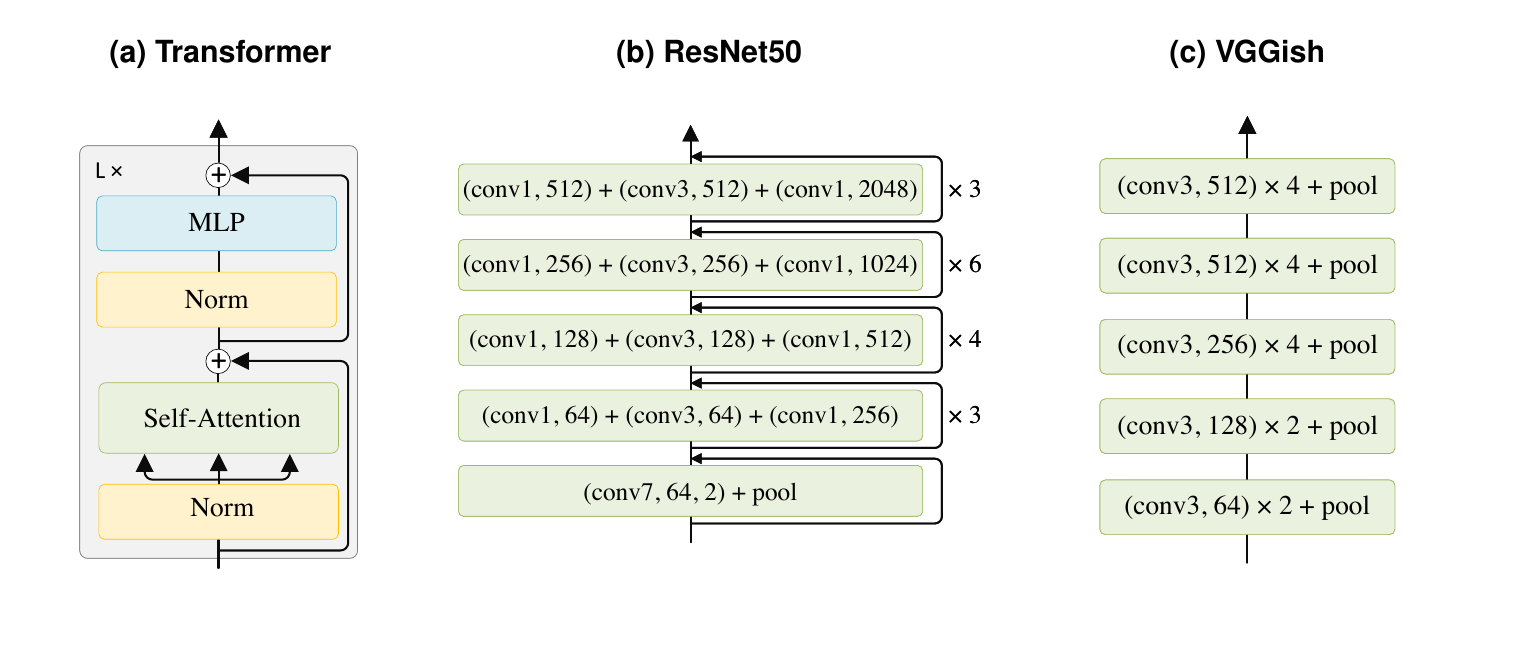
Language encoders, visual encoders, and audio encoders provide the first representation layer before cross-modal alignment.
Use this survey when citing: encoder choices for audio, vision, and language in AVL systems.
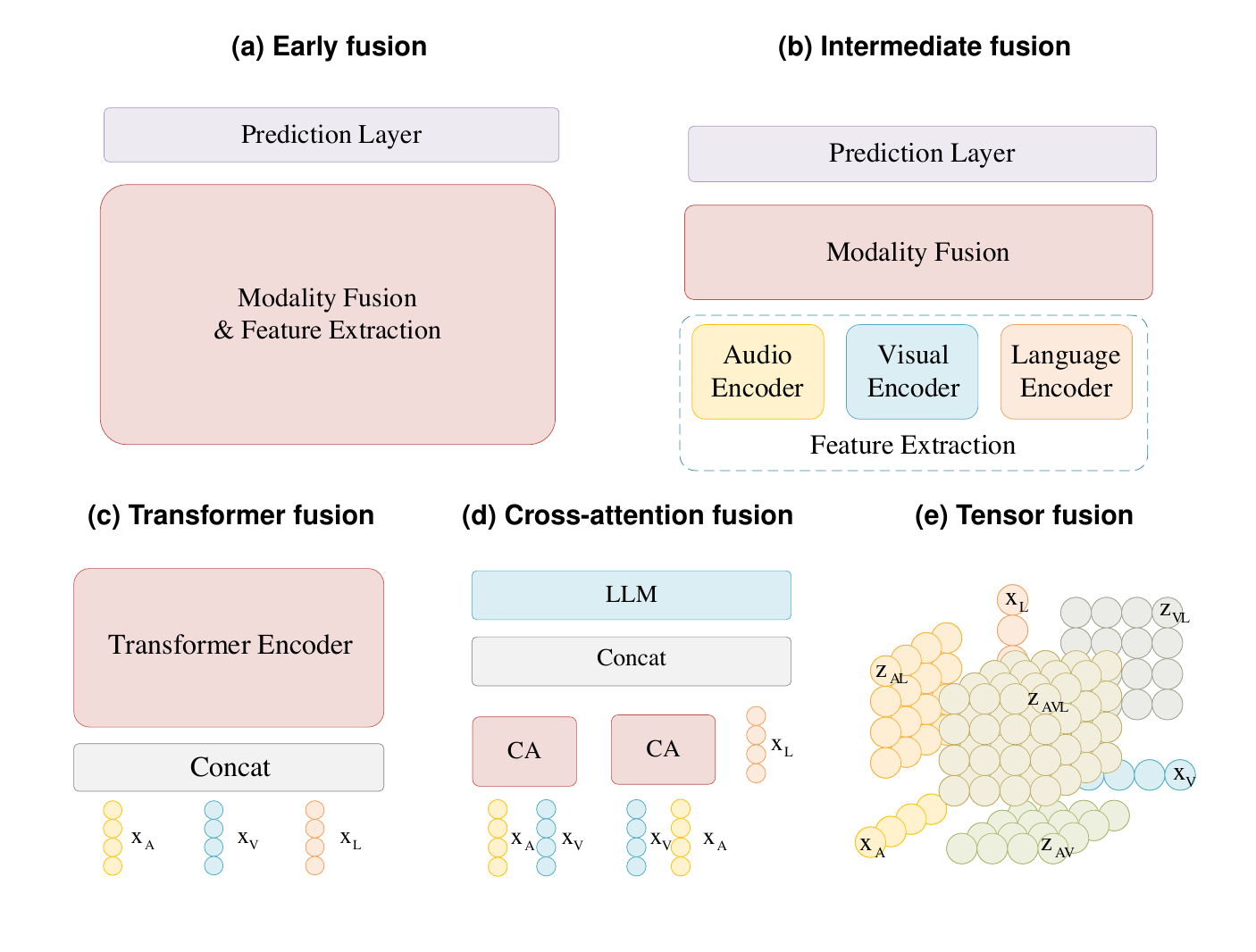
Early fusion, intermediate fusion, Transformer fusion, cross-attention fusion, tensor fusion, and MLP-based fusion describe where and how modality evidence is combined.
Use this survey when citing: alignment and fusion mechanisms in AVL models.
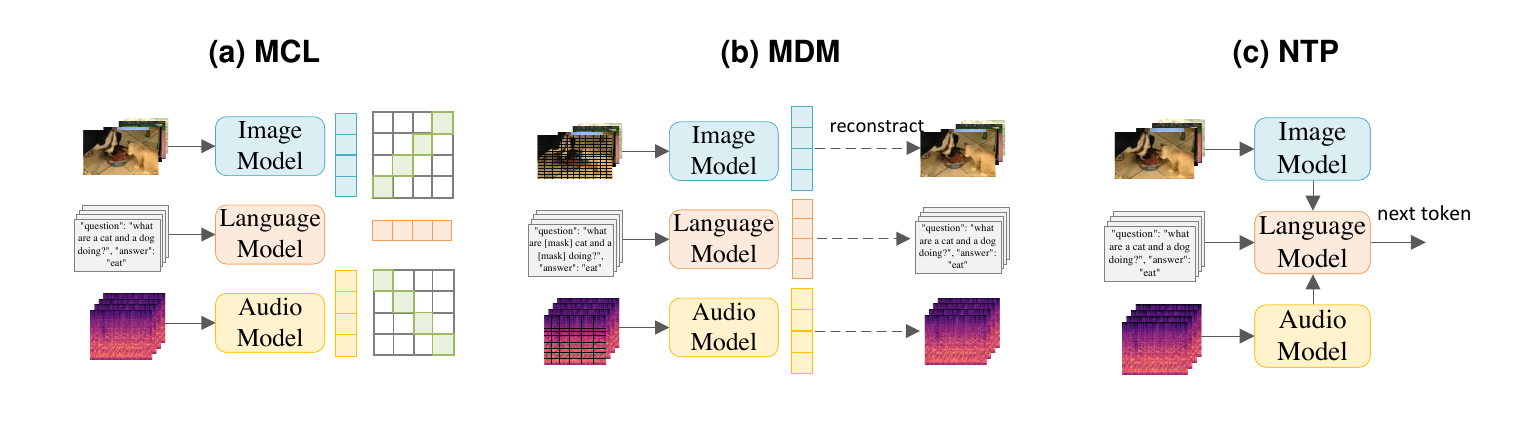
Multimodal contrastive learning, masked data modeling, and next-token prediction define common objectives for learning across modalities.
Use this survey when citing: pretraining objectives for audio-visual-language representation learning.
The matrix is a compact guide to task formulations, representative datasets, and metrics. Expand a row for input/output details.
| Task | What it evaluates | Datasets | Metrics | Details |
|---|---|---|---|---|
| MAR | Action recognition from multimodal cues | Kinetics-400, EPIC-KITCHENS | Top-1, Top-5 | Input/outputvideo/audio/text cues → action labels |
| MER | Emotion and sentiment inference | IEMOCAP, MELD, CMU-MOSEI | Accuracy, F1 | Input/outputdialogue signals → emotion or sentiment |
| AVQA | Question answering over audiovisual scenes | Music-AVQA, VAQA | Answer accuracy | Input/outputaudiovisual scene + question → answer |
| AVOL | Object or region localization | RefCOCO, Flickr-SoundNet | Localization accuracy, IoU | Input/outputaudiovisual-textual query → localized object |
| AVEL | Event class and temporal location | AVE, LLP | Accuracy, F1 | Input/outputaudiovisual stream → event class and time span |
| CMR | Retrieval across modalities | MSR-VTT, AudioCaps | Recall@K, median rank | Input/outputquery in one modality → ranked items in another |
| AVSR | Speech transcription from audio and visual cues | LRS2, LRS3 | WER | Input/outputspeech video + audio → transcript |
| AVVC | Caption generation from audiovisual clips | MSR-VTT, ActivityNet Captions | BLEU, METEOR, CIDEr | Input/outputaudiovisual clip → caption |
| ViG | Video generation from text or audio conditions | AudioSet-Cap, Landscape | FVD, CLIP similarity | Input/outputtext/audio conditions → video |
AVL models combine modality-specific encoders, cross-modal alignment, and task adaptation in latent spaces that are difficult to inspect.
Use this survey when citing: the need for attribution across audio, visual, and language evidence.
Many tasks require knowing whether a sound, visual event, and language description refer to the same moment or event.
Use this survey when citing: limitations of current AVL benchmarks for fine-grained alignment.
Long videos, multiple speakers, overlapping sounds, and cluttered scenes expose reasoning gaps that coarse task accuracy does not fully capture.
Use this survey when citing: the need for long-context and multi-source AVL evaluation.
Separate encoders and heavy fusion modules increase memory and compute cost, making local, private, or real-time deployment difficult.
Use this survey when citing: deployment constraints in heavy trimodal systems.
Figures from the paper
The gallery keeps each figure to one takeaway so the page supports navigation instead of repeating the full paper.
Open problems
Current AVL benchmarks support broad task evaluation, but they still leave important questions under-tested.
AVL models combine modality-specific encoders, cross-modal alignment, and task adaptation in latent spaces that are difficult to inspect.
Many tasks require knowing whether a sound, visual event, and language description refer to the same moment or event.
Long videos, multiple speakers, overlapping sounds, and cluttered scenes expose reasoning gaps that coarse task accuracy does not fully capture.
Separate encoders and heavy fusion modules increase memory and compute cost, making local, private, or real-time deployment difficult.
Citation
If this survey helps you define audio-visual-language modeling, organize AVL tasks or benchmarks, or motivate open problems in trimodal learning, please cite the preprint version below. Citation metadata will be updated after publication.
@article{zhang2025recent,
title={RECENT ADVANCES IN AUDIO-VISUAL-LANGUAGE MODELING},
author={Zhang, Kairui and Abdallah, Zahraa S and Lewis, Martha},
journal={Authorea Preprints},
publisher={Authorea}
}Public project resources will be updated here after publication or repository release. The current page is intended as a preprint guide and citation entry point.